본 글은 "바닥부터 시작하는 딥러닝" 책을 바탕으로 작성되었습니다.
4.1 데이터에서 학습한다.
- '학습'은 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것이다.
- 신경망이 학습할 수 있도록 도와주는 지표는 '손실 함수'로, 결과값을 가장 적게 만드는 가중치 매개변수를 찾는 것이 학습 목표이다.
4.1.1 데이터 주도 학습
- 기계학습은 사람의 개입을 최소화하고, 모아진 데이터로부터 패턴을 찾으려고 시도한다.
예시 1) 이미지에서 특징을 추출하고, 그 특징의 패턴을 기계학습 기술로 학습하는 방법
- 이미지 특징인 이미지 데이터를 벡터로 변경하고, 지도 학습 방식의 대표 분류 기법인 SVM, KNN등으로 학습할 수 있다.

4.1.2 훈련 데이터와 시험 데이터
- 기계학습에서는 범용적 모델을 만들기 위해, 훈련 데이터와 시험 데이터로 나뉘어 학습 및 실험을 진행한다.
1) 훈련 데이터만 사용하여 학습하면서, 최적의 매개변수를 찾는다.
2) 시험 데이터를 사용하여, 훈련한 모델의 실력을 평가한다.
- 하나의 데이터셋만 학습하면, 학습한 데이터셋만 평가할 수 있는 문제가 있다. 이렇게 하나의 데이터셋에만 지나치게 최적화된 상태를 "오버피팅"이라고 한다.
4.2 손실 함수
- 신경망 학습에서는 현재 상태를 '하나의 지표'라고 하고, 해당 지표를 가장 좋게 만들기 위해 가중치 매개변수의 값을 탐색한다.
- 신경망 학습에서 사용하는 지표를 "손실 함수"라고 한다.
- 손실 함수는 임의 함수를 사용할 수 있지만, 보통은 오차제곱합과 교차 엔트로피 오차를 사용한다
.4.2.1 오차제곱합
- 손실 함수에서 가장 많이 쓰는 함수이다.
- 그림2에서 yk는 신경망이 추정한 값, tk는 정답 레이블을 의미한다.

- 아래는 오차제곱합을 파이썬으로, y와 t는 넘파이 배열이다.
def sum_squares_error(y, t):
return 0.5 * np.sum((y-t)**2)- 아래는 위 코드를 실행한 예시 2가지에 대한 결과이다.
- 2가지 모두 정답은 2이지만, 2번째 예시에서는 신경망 출력이 7이 가장 높음으로써 1번째 예시보다 정확도가 떨어진다.
- 오차제곱합 기준으로 1번째 예시가 오차가 적으니, 정답에 더 가까울 것이라고 판단할 수 있다.

4.2.2 교차 엔트로피 오차
- 그림 4에서 log는 밑이 e인 자연로그이고, yk는 신경망이 추정한 값, tk는 정답 레이블이다.
- tk는 정답에 해당하는 인덱스의 원소만 1이고, 나머지는 0이다.
- 답을 추정할 때는 tk가 1일 때 yk의 자연로그를 계산하는 식이 된다.
(tk가 0일 때, logyk와 곱해도 0이 되어 결과에 영향이 없다.)
- 교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정한다.
(정답 레이블에서 값이 1인 정답일 때, 신경망의 출력이 0.6면 교차 엔트로피 오차는 -log0.6 = 0.51이 된다.)

- 교차 엔트로피 오차를 구현하면, 아래와 같다.
- y와 t는 넘파이 배열이다.
- 코드에서 np.log 계산 시, delta를 더한 이유는 np.log 함수에 0을 입력하면 마이너스 무한대인 -inf가 출력되기 때문이다.
(아주 작인 값인 delta를 더해서, 마이너스 무한대가 발생하지 않도록 방지한 것이다.)
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))- 아래는 교차 엔트로피 오차 함수를 실행한 결과이다.
- 오차 값이 더 작은 첫번째 추정이 정답 가능성이 높다고 판단할 수 있다.

4.2.3 미니배치 학습
- 기계학습은 훈련 데이터에 대한 손실 함수의 값을 구하고, 해당 값을 줄여주는 매개변수를 찾으며 학습된다.
- n개의 훈련 데이터가 있으면, 각각의 훈련 데이터에 대한 손실 함수 값들을 구하고 합하여 지표로 삼아야 한다.
- 교차 엔트로피 오차 함수로 n개의 훈련 데이터에 대한 손실 함수 값을 구하기 위한 수식은 아래와 같다.
- 그림 6에 존재하는 수식은 그림 4 수식에서 N개의 데이터로 확장한 수식이며,
마지막에만 N분의 1로 나누어 '평균 손실 함수'를 구한다.

- MNIST 데이터셋의 경우와 같이 훈련 데이터가 60,000개 정도 있으면, 각 데이터 대상으로 손실 함수의 합을 구하는데 많은 시간이 소요된다.
- 위와 같은 문제점으로, 데이터 일부를 추려 전체의 근사치를 이용해 계산할 수 있다.
- 신경망 학습에서도 훈련 데이터로부터 일부만 골라 학습하는데, 일부를 '미니배치'라고 한다.
- 많은 데이터 중, 무작위로 일부만 뽑아 학습하는 방법을 '미니 배치 학습'이라고 한다.
- 아래는 MNIST 데이터셋을 읽어오는 코드이다.
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
print(x_train.shape)
print(t_train.shape)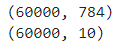
- 아래는 훈련 데이터인 MNIST 데이터셋에서 무작위로 10장 빼내는 코드이다.
train_size = x_train.shape[0]
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]- np.random.choice()는 지정한 범위의 수 중에서 무작위로 원하는 개수만 꺼낼 수 있는 함수로,
np.random.choice(60000, 10)은 0이상 60000미만의 수 중, 무작위로 10개 추출해달라는 코드이다.

4.2.4 (배치용) 교차 엔트로피 오차 구현하기
- 교차 엔트로피 오차 함수에서 데이터 하나의 경우와 데이터가 배치로 묶여 입력될 경우 모두 처리하기 위해, 아래와 같이 코드를 구현할 수 있다.
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size- 정답 레이블이 원-핫 인코딩이 아닌 숫자 레이블로 주어졌을 때, 교차 엔트로피 오차 코드는 아래와 같이 구현할 수 있다.
- np.arange(batch_size)는 0 ~ (batch_size - 1)까지 배열을 생성한다.
- t에는 레이블에는 숫자 레이블이 저장되어 있으므로, y[np.arange(batch_size), t]는 각 데이터의 정답 레이블에 해당하는 신경망의 출력을 추출한다.
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size4.2.5 왜 손실 함수를 설정하는가?
- 가중치 매개변수의 손실 함수의 미분 값에 따라, 가중치 매개변수 값을 조금 변화 시켜 손실 함수의 값을 줄일 수 있다.
- 정확도를 지표로 두지 않는 이유는 '미분 값이 대부분 0이 되어, 매개변수를 갱신할 수 없기 때문'이다.
(정확도는 매개 변수를 조금 변화 시켜도, 거의 반응을 보이지 않기 때문이다.)
- 계단 함수와 시그모이드 함수도 기울기를 살펴보면, 계단 함수는 기울기가 대부분 0이지만 시그모이드 함수는 기울기가 0이 되지 않는다. 이러한 이유로, 계단 함수는 활성화 함수로 사용되지 않는다.
4.3 수치 미분
4.3.1 미분
- 미분은 한순간의 변화량을 표시한 것으로, 수식은 아래와 같다.
- x의 작은 변화가 함수 f(x)를 얼마나 변화 시키냐를 의미한다.
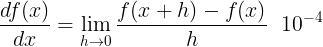
- 아래는 미분을 계산하는 코드이다.
- 그림 9의 수식을 그대로 표현하려면, h에 작은 값을 대입해 계산할 수 있다.
def numerical_diff(f, x):
h = 1e-50
return (f(x + h) - f(x)) / h
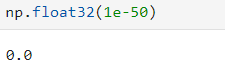
- 하지만 1e-50은 0.00...1형태에서 소수점 아래 0이 50개라는 의미인데, 이 방식은 반올림 오차 문제가 발생한다.
- 1e-50을 float32형으로 나타내면 0.0이 되어 올바른 표현이 불가능하다.
- 해당 부분은 개선하여, h값을 10-4정도 값으로 수정한다. (해당 값 정도면, 좋은 결과를 얻을 수 있는 것으로 알려져 있다.)
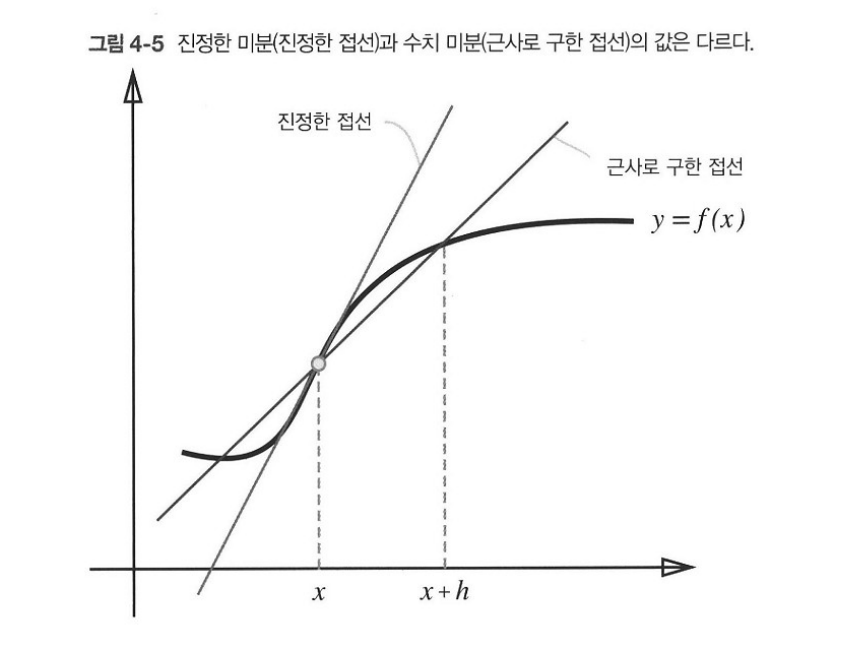
- 위 코드에서는 함수 f의 차분에 계산 오차가 존재한다.
- 진정한 미분은 x 위치의 함수 기울기에 해당하지만, 해당 식에서는 (x+h)와 x 사이의 기울기에 해당하므로 기존 미분과는 차이가 있다.
- 해당 차이는 h를 무한히 0으로 좁히는 것이 불가능해 생기는 한계이다.
- 위 오차를 줄이기 위해, (x+h)와 (x-h)일 때 함수 f의 차분을 계산하는 방법을 쓰기도 한다.
이는 x 중심으로 전후 차분을 계산하는 의미에서 '중심 차분' 또는 '중앙 차분' 이라고 한다.
- (x+h)와 x의 차분을 '전방차분'이라고 한다.
- 위 2가지 개선점을 적용해 수치 미분을 다시 구현하면, 아래와 같다.
(수치 미분: 아주 작은 차분으로 미분하는 것)
def numerical_diff(f, x):
h = 1e-4 #0.0001
return (f(x + h) - f(x - h)) / (2 * h)4.3.2 수치 미분의 예
- 앞에서 구현한 수치 미분을 사용하여, 아래 간단한 2차 함수를 미분한다.
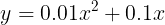
- 그림 12 수식을 간단히 파이썬으로 구현하면, 아래와 같다.
def func_1(x):
return 0.01*x**2 + 0.1*x- 해당 함수를 그래프로 그려보면 아래와 같다.
import numpy as np
import matplotlib.pylab as plt
x = np.arange(0.0, 20.0, 0.1) #0~19까지 0.1 간격의 배열 x를 만들음
y = func_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
plt.plot(x, y)
plt.show()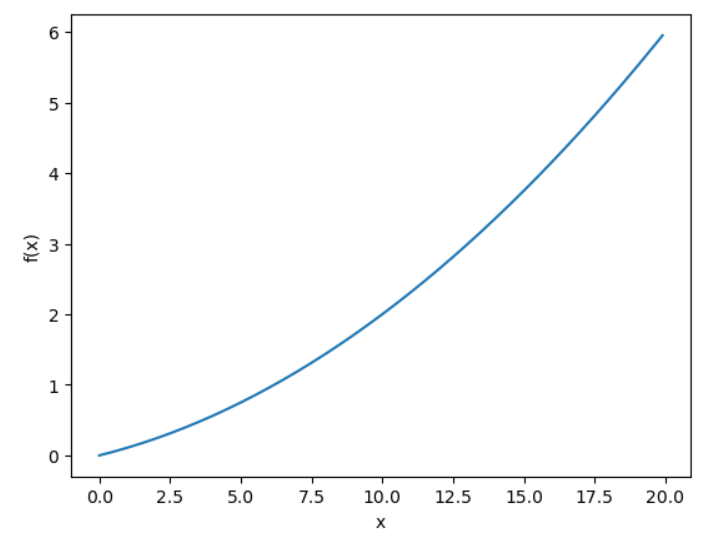
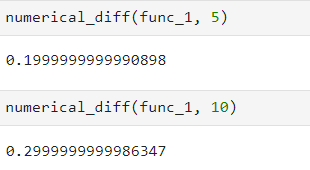
- 아래는 x값이 5와 10일 때, 위 2차 함수의 미분을 계산한 결과이다.
- 각각 반올림해서 0.2와 0.3이 나온 것을 확인할 수 있으며, 실제로 거의 같은 값이라고 해도 될 만큼 작은 오차이다.
- 이렇게 계산된 미분 값이 x에 대한 f(x)의 변화량으로, 함수의 기울기에 해당된다.
- f(x)=0.01x2 + 0.1x 의 해석적 해는 df(x)/dx = 0.02x + 0.1 이다.
4.3.3 편미분
- 아래는 인수들의 제곱 합을 계산하는 단순한 식이다.
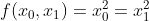
- 위 수식을 파이썬으로 구현하면, 아래와 같다.
def func_2(x):
return x[0]**2 + x[1]**2 #return np.sum(x**2) 같은 의미- 그림15의 수식은 변수가 2개이므로, 미분을 할 때 어떤 변수에 대한 미분인지 구별해야 한다.
- 변수가 여러개인 함수에 대한 미분을 "편미분"이라고 한다.
- 위 수식의 편미분 수식을 ∂f/∂x0 또는 ∂f/∂x1 이라고 나타낼 수 있다.
- 편미분은 여러 변수 중 목표 변수 하나에 초점을 맞추고, 다른 변수는 값을 고정시킨다.
4.4 기울기
- 이전 방식과 달리, 편미분을 하나의 변수별로가 아닌 변수를 동시에 계산할 수 있다.
- (x0, x1) 양쪽 편미분을 묶어서 (∂f/∂x0, ∂f/∂x1)을 계산할 때, (∂f/∂x0, ∂f/∂x1)처럼 모든 변수의 편미분을 벡터로 정리한 것을 "기울기"라고 한다.
- 기울기는 예를 들어, 아래와 같이 구현할 수 있다.
- np.zeros_like(x)는 x와 형상이 같고, 그 원소가 모두 0인 배열을 생성한다.
- numerical_gradient(f, x) 함수의 인자 f는 함수이고 x는 넘파이 배열로, x의 각 원소에 대해 수치 미분을 구한다.
def numerical_gradient(f, x):
h = 1e-4 #0.0001
grad = np.zeros_like(x) #x와 형상이 같은 배열 생성
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h) 계산
x[idx] = tmp_val + h
fxh1 = f(x)
#f(x-h) 계산
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val #값 복원
return grad- 아래는 세점 (3, 4), (0, 2), (3, 0)에서의 기울기를 구한 결과이다.
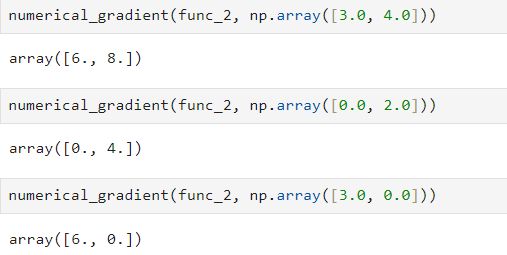
- 기울기는 각 지점에서 낮아지는 방향을 가르키므로, 기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향이다.
4.4.1 경사법(경사 하강법)
- 최적의 손실함수의 최솟값을 알고 싶지만, 매개변수의 공간이 광대하여, 어떤 값이 최솟값인지 짐작할 수 없다.
이러한 상황에서 기울기를 잘 사용하여, 함수의 가능한 작은 최솟 값을 찾으려는 것이 '경사법'이다.
- 그러나, 각 지점의 함수 값 낮추는 방향을 기울기가 제시하기 때문에 정말 최솟값인지 보장할 수 없다.
(실제로 복잡한 함수에서는 기울기가 가리키는 방향에 최솟값이 없는 경우가 대부분이다.)
- 한정된 범위내에서 최솟값일 경우에 기울기는 0이므로, 경사법에서도 기울기가 0인 장소를 찾는다.
- 경사법은 현 위치에서 기울어진 방향으로 일정한 거리만큼 이동하고, 다시 현 방향에서 기울기를 구해 이동한다.
이러한 반복 과정을 통해, 함수의 값을 점차 줄이는 것을 "경사법"이라고 한다.
- 경사법의 수식은 아래와 같다.
- η(eta, 에타)는 갱신하는 양을 나타내며, 신경망 학습에서는 학습률이라고 한다.
(매개변수 값을 얼마나 갱신하느냐를 정하는 것이 학습률이다.)
- 그림17의 수식은 1회에 해당하는 갱신으로, 경사법은 이를 반복하면서 함수의 값을 줄여나간다.
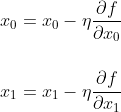
- 학습률 값은 0.01이나 0.001 등 미리 특정 값으로 정해둬야 하는데, 너무 크거나 작으면 최솟값을 찾을 수 없다.
- 신경망 학습에서는 학습률 값을 변경하며, 올바르게 학습하고 있는지 확인하면서 진행된다.
- 아래는 경사 하강법을 간단히 구현한 코드이다.
- 인수 f는 최적화하려는 함수, init_x는 초깃값, lr은 학습률, step_num은 경사법에 따른 반복 횟수를 의미한다.
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x- 아래는 경사 하강법 코드를 활용하여, 그림 18 수식에 대한 최솟값을 구하는 예시이다.
- 그림 19에 출력된 결과를 보면, -6.1e-10과 8.1e-10으로 거의 (0,0)에 가까운 결과이다.
(최솟값은 0,0이므로 경사법으로 거의 정확한 결과를 얻은 것이다.)
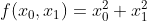

4.4.2 신경망에서의 기울기
- 신경망 학습에서도 가중치 매개변수에 대한 손실 함수의 기울기를 구해야 한다.
- 신경망의 기울기를 구한 후, 경사법에 따라 가중치 매개변수를 갱신한다.
4.5 학습 알고리즘 구현하기
- 신경망 학습 절차는 아래와 같다.
① 전제: 신경망에는 가중치와 편향이 존재하며, 이를 훈련 데이터에 적응하도록 조정하는 과정을 '학습'이라고 한다.
② 미니 배치: 훈련 데이터 중 일부를 무작위로 가져온 데이터로, 미니 배치 손실 함수 값을 줄이는 것이 목표이다.
③ 기울기 산출: 미니배치 손실 함수 값을 줄이기 위해, 각 가중치 매개변수의 기울기를 구한다.
④ 매개변수 갱신: 가중치 매개변수를 기울기 방향으로 아주 조금 갱신한다.
⑤ 반복 : 미니배치 ~ 매개변수 갱신까지의 순서를 반복한다.
- 위 절차는 미니배치로 선별된 일부 데이터에서, 경사 하강법으로 매개변수를 갱신하는 방법이므로 "확률적 경사 하강법"이라고 한다. 영어로는 SGD라고 한다.
- 이후 내용에서는 솔글씨 학습하는 신경망을 구성하는 내용으로, 2층 신경망(은닉층이 1개인 네트워크)을 대상으로 MNIST 데이터셋을 사용하여 학습을 수행한다.
4.5.1 2층 신경망 클래스 구현하기
- 2층 신경망을 하나의 클래스로 구현하는 것부터 시작한다.
import sys, os
sys.path.append(os.pardir)
from common.functions import *
from common.gradient import numerical_gradient
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 예측(추론)을 수행한다.
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
# 손실 함수의 값을 구한다.
# x: 입력 데이터, t: 정답 레이블
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
# 정확도를 구한다.
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# 가중치 매개변수의 기울기를 구한다.
# x: 입력 데이터, t: 정답 레이블
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads4.5.2 미니배치 학습 구현하기
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
train_loss_list = []
#하이퍼파라미터 (=학습률 같은 매개변수, 사람이 직접 설정해야함)
iters_num = 10000 #반복 횟수
train_size = x_train.shape[0]
batch_size = 100 #미니배치 크기
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
for i in range(iters_num):
# 미니배치 획득
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 기울기 계산
grad = network.numerical_gradient(x_batch, t_batch)
# 매개변수 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 학습 경과 기록
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)4.5.3 시험 데이터로 평가하기
- 미니배치 학습으로 실수 함수 값이 줄어든다고 해서, 훈련 데이터 외의 데이터셋에서도 적용되는 것인지 확실하지 않다.
- 신경망 학습에서는 훈련 데이터 외의 데이터들도 올바르게 인식되는지 확인해야 한다. (=오버피팅)
- 신경망 학습의 목표는 범용적인 능력을 익히는 것이다.
- 본 내용에서는 1에폭별로 훈련 데이터와 시험 데이터에 대한 정확도를 기록한다.
(에폭은 학습에서 훈력 데이터를 모두 소진했을 때의 횟수에 해당한다.)
- 평가가 제대로 이뤄지기 위해, 앞 구현에서 수정되었다.
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
train_loss_list = []
train_acc_list = []
test_acc_list = []
#1에폭당 반복 수
iter_per_epoch = max(train_size / batch_size, 1)
#하이퍼파라미터 (=학습률 같은 매개변수, 사람이 직접 설정해야함)
iters_num = 10000 #반복 횟수
train_size = x_train.shape[0]
batch_size = 100 #미니배치 크기
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
for i in range(iters_num):
# 미니배치 획득
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 기울기 계산
grad = network.numerical_gradient(x_batch, t_batch)
# 매개변수 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 학습 경과 기록
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 1에폭당 정확도 계산
if i % iter_per_echo == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))'AI' 카테고리의 다른 글
| Building Systems with the ChatGPT API (0) | 2024.08.03 |
|---|---|
| Chapter 6. 학습 관련 기술들 (0) | 2024.07.13 |
| Chapter 5. 오차역전파법 (0) | 2024.06.30 |
| Chapter 3. 신경망 (0) | 2024.06.18 |
| Chapter2. 퍼셉트론 (1) | 2024.06.17 |



